We at Kae Capital have witnessed an increased interest in modern data stack this year. We have looked at many data stack startups building from India. Some of our early-stage portfolio companies have also realized the need for solutions to effectively manage data infrastructure. This pushed us to do a deeper dive into this space. I am penning down my understanding of the current modern data stack and some of the recent developments.
Data Stack is a suite of softwares/ tools used to manage data to make use of it for decision-making. Cloud service providers enabled data storage in an easy, fast and cost-effective manner compared to traditional on-prem storage. This led to Modern Data Stack where the data is stored on cloud and stack consists of cloud-native tools that help you store, process and analyze data.
Pivotal moment in Modern Data Stack (MDS) was the introduction of cloud data warehouses around 2012. Redshift, Bigquery and Synapse are the cloud-native data warehouses offered by the three major cloud service providers — Amazon AWS, GCP (Google Cloud Platform) and Microsoft Azure respectively. Another popular cloud data warehouse player is Snowflake, which can be hosted on any of the three major clouds. Cloud Data warehouses made storing and using data easier and their consumption-based pricing provided the flexibility to adopt and scale.
The global data management software market was over $70B in 2021 and is expected to grow to $150B by 2027. The interest in MDS has increased in the last few years. According to PitchBook, the venture funding in the data startups tripled from $2.5B in 2020 to $7.5B in 2021. Companies are moving towards data-driven decision-making, which has increased the pull for real-time data processing and BI/ analytics. AI/ ML and IoT have become the major drivers for the development of data infrastructure. Data gives a competitive advantage, therefore every company wants to become a data company.

The data companies have seen explosive growth. Snowflake is a listed company, it was one of the biggest IPO ($3.36B) in the history of software. Its current market cap is more than $45B. Its business has grown well, standing at ARR of $1.2B+ in FY22. It has 6,800+ total customers and 246 customers with greater than $1M in trailing 12-month product revenue contributions. Snowflake has one of the best NRRs in SaaS of 171%. Here is its growth slide from Q2FY23 earnings presentation-

Databricks, a competitor of Snowflake, has raised around $3.8Bn and is valued at more than $38Bn. It closed 2021 with an ARR of $800Mn with 7000+ customers and an NRR of more than 150%.
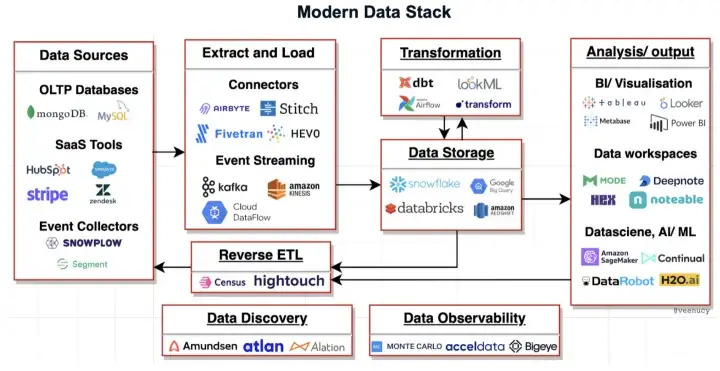
Coming back to the value chain of data. We can’t run analysis/ queries on raw data, to do data analysis or to build ML models we need the data to be in a processed format. First, we need to collect raw data from different sources, then we need to move and store data at a centralized location, post which it needs to be transformed for analytics.

Elaborating on the various parts of the modern data stack shown above.
Data Sources–
Companies generate a lot of data from different sources.
- OLTP Databases– OLTP (Online transactional processing) systems handle large volumes of transactional data. It consists of user information and operational data generated by users such as e-commerce purchases and online banking. A standard database management system (DBMS) is an OLTP system. Mysql, mongoDB and Postgres are some well-known databases.
- SaaS tools– Companies use many SaaS tools to run their business such as CRM tools to store sales, marketing and customer success data (Salesforce, Hubspot), payment/billing softwares (Stripe).
- Event Collectors– Nowadays every possible touch point with the users is recorded as an event, which is used for analysis. It includes recording every click on websites and apps. Segment and Snowplow are popular choices for collecting events.
Extract and Load
All data from different data sources is extracted and loaded to a centralized data warehouse/ data lake. Earlier, the sequence used to be ETL- data is first extracted then transformed and then loaded into the data warehouse. Now, it has evolved to ELT- data is extracted and loaded into the datahouse and later transformed at the warehouse itself.
Airbyte, Fivetran, Hevodata are the popular ingestion softwares, they provide multiple connectors to extract and load data. They usually load the data in batches, whereas Apache Kafka and Amazon kinesis can stream data directly into the data warehouse in real time.
Data Storage
Ingestion tools stored the data at a cloud data warehouse or data lake. Data warehouse stores structured data (tables) that can be directly queried for analytics. The popular cloud data warehouses are Snowflake, Google Bigquery and Amazon Redshift.
Whereas Data Lake stores a large pool of raw data- structured/ unstructured/semi-structured. It can store any form of data- audio, video, tables. It can load and store data without transformation. It is useful where you need to collect and store a lot of data but not necessarily need to process and analyze it right away. Databricks is one of the most popular data lake. Data lake and data warehouse complement each other and most organizations use both.
Data Transformation
After storing the data, it is transformed directly in the warehouse into a structure ready for analysis, which is used by the data science and business team to run different analytics and ML models. Dbt, Airflow and LookML are the most popular transformation tools.
Analysis/ Output
The transformed data can used for different purposes-
- BI/ Visualisation– These tools enable business users to derive insights. They provide a dashboard view with graphs/ pie charts which facilitates business visibility. Tableau, Looker, Power BI are some popular BI tools.
- Data Workspaces– These tools make it easier for different users to query, visualize and collaborate on data and create dashboards. Some of the emerging data workspaces tools are hex, deepnote, mode, noteable.
- Data Science, AI/ ML– Data scientists can run ML models on data with help of these tools. Some of the popular tools are Sagemaker, Continual.
- Reverse ETL– It syncs back the aggregated data to SaaS tools like customer support, sales and marketing to provide full consumer visibility to business users at their primary software. Census and Hightouch are the popular reverse ETL tools.
Data Monitoring and Governance –
We also need to maintain operational data hygiene. There are three major data ops categories of softwares, which help in reducing the risk, operational complexity and cost of the cloud data-
- Data Observability– Testing and monitoring pipelines are developed to detect and resolve errors or issues. Monte Carlo, Acceldata and Great Expectations are the popular choices.
- Data Discovery– Data cataloguing, documentation and discovery so that people can discover the right tables for their use. Atlan, Amundsen, and Alation are the popular tools here.
- Data Security– Access control and data security to safeguard the company’s data. Control which employee has access to which data. Cyral, Immuta are the emerging tools in this category.
Modern Data Stack is constantly evolving. Some of the recent developments in the stack-
- Introduction of Data lakehouse by databricks and Unistore by Snowflake- Databricks has introduced the data lakehouse. A data lakehouse combines the flexibility, cost efficiency of a data lake with the data management capabilities of a data warehouse. It is an open data management architecture to enable analytics, BI and ML on all data types.

Snowflake Unistore enables working with transactional and analytical data in a single unified platform. Unistore can store both transactional and analytical data on a data cloud and query it for analysis.

- Data Marketplace — Snowflake has become a behemoth and is now adopting a platform approach enabling products to develop on top of it. Idea is companies can use the native application framework to build native Snowflake apps that can be distributed through Snowflake Marketplace. Snowflake customers can discover, evaluate and run the apps in their accounts, removing the need to move data, thereby improving privacy and security. It is enabling customers to bring apps to data rather than moving data to different apps. It eliminates the delay and cost of traditional ETL with direct access to ready-to-query data and pre-built SaaS connectors.

- MDSaaS– Modern Data Stack as a service. Data Stack is complex and evaluating tools and setting up the entire stack can be a challenging time taking process. There are low/no-code platforms that provide all the tools needed to go from data sources to interactive dashboards. Some of the emerging startups here are Selfr.io, Octolis.
We at Kae Capital are very keen on the modern data stack and actively follow developments in this space. Please write to me at veenu@kae-capital.com if you are building in the data stack or if you want to discuss different SaaS themes.



